大文件上传?断点续传?
在工作场景的上传场景中,大文件的上传如果不经处理,那么就会耗时很久,并且容易出现上传了大半突然因网络波动等原因失败了,用户又要重新上传,重头开始。
面对这种情况,需要有一个技术方案去优化大文件上传的逻辑。
1. 文件分片

首先,为了优化并解决这种大文件上传问题,需要将文件进行分片处理,将整个大文件拆分成一个个小文件,然后再进行小文件的逐个上传。如上图所示。
function createFileChunks(file: File, chunkSize: number) {
const result: Blob[] = [];
for (let i = 0; i < file.size; i += chunkSize) {
result.push(file.slice(i, i + chunkSize));
}
return result;
}
以上是一个分片的函数,输入文件以及每个分片的大小,输出分片数组。由于file对象持有的是文件的基本信息引用(如size、type、name等),并不会将文件整个读到内存中,所以其运算速度是很快的。
2. 断点续传
虽然做到了文件分片,但是一但某个文件上传失败,或者用户不小心刷新了页面需要重新上传,需要怎么做到从断开处继续上传呢?

可以从上面示意图看到,主要关键点在于如何标识出是同一份文件,只有能够精准识别出同一份文件,服务器才能知道这份文件已上传部分有哪些。
而这也很简单,在webpack打包中,为了标识文件内容是否有变更,一般会在文件名上包含content hash的值,这同样适用于上传文件。
function createFileHash(chunks: Blob[]) {
return new Promise((resolve, reject) => {
const spark = new SparkMD5();
function _read(i: number) {
if (i >= chunks.length) {
resolve(spark.end());
return;
}
const blob = chunks[i];
const reader = new FileReader();
reader.onload = (e) => {
const bytes = e.target?.result;
spark.append(bytes);
_read(i + 1);
}
reader.readAsArrayBuffer(blob);
}
_read(0);
});
}
在上面示例代码中,使用了第三方库spark-md5用以生成文件的hash值,并用增量算法将第一步得到的文件分片进行逐片的读取并计算,避免了因文件太大导致浏览器运算缓慢甚至崩溃。
3. 进一步优化
实际运行中,对文件的hash值计算会比较耗时,所以为了减少主线程的占用,可以采用web worker或者用任务分片的方式进行进一步的优化。
新建fileHashWorker.js文件,并将hash计算逻辑移动到文件内部,内容如下:
// fileHashWorker.js(worker线程)
importScripts('./spark-md5.js'); // 导入spark-md5
self.addEventListener('message', e => {
const chunks = e.data.chunks || []
const spark = new SparkMD5();
function _read(i) {
if (i >= chunks.length) {
postMessage(spark.end());
return;
}
const blob = chunks[i];
const reader = new FileReader();
reader.onload = (e) => {
const bytes = e.target?.result;
spark.append(bytes);
_read(i + 1);
}
reader.readAsArrayBuffer(blob);
}
_read(0);
});
然后修改原先的createFileHash函数如下:
function createFileHash(chunks) {
return new Promise((resolve, reject) => {
const worker = new Worker('/fileHashWorker.js'); // 创建 worker
worker.addEventListener('message', e => {
resolve(e.data);
worker.terminate(); // 关闭 worker
});
worker.postMessage({ chunks });
});
}
需要注意在生产环境中使用Worker还需要额外注意浏览器兼容性,当浏览器不兼容时可以回退到任务切片模式或者仅在主线程计算。
4. 超大文件切片
在代码实现中可以发现,越大的文件生成hash的时间就越长,因为文件越大同等大小的chunks数量更多,读取与计算自然就更耗时。那么面对超大的文件应该如何优化呢?我们可以先将超大文件进行大粒度分片,然后再进行二次细粒度分片即可(甚至可以进行三次四次分片)。
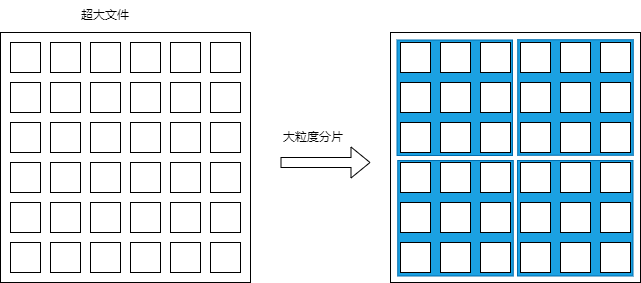
这样,我们一开始仅需要计算首个大块的内容hash, 后续的chunks可在后续上传途中逐个解析。